C言語プログラマがPythonのお勉強で気になったことメモ(その2)
前回に引き続きです。 stacked-tip.hateblo.jp
今回も、こちらの書籍のコードを写経しながら、気になって調べたことを紹介していきます。
2章で気になって調べたこと
pandas.Series.dt.strftime()の引数のフォーマット
analyze_data['order_accept_month'] = analyze_data['order_accept_data'].dt.strftime('%Y%m')
で出てきましたpandas.Series.dt.strftime()は、要素を日付フォーマット(date format)に変換するメソッドです。
公式ドキュメントによれば、このメソッドの引数にはpython standard libraryに準拠したフォーマット文字列(そしてこれは1989 C standardをベースとしている)を入れるよう書いてあります。
%Yは4桁の年、%mは2桁の月を、それぞれ意味しています。
pandas.DataFrame.groupby()メソッドとDataFrameGroupByオブジェクト
pandas.DataFrame.groupby()メソッドを使うと、指定したキーの種類ごとにデータをグルーピングしてくれます。
このメソッドの返値はDataFrameGroupByオブジェクトという専用のオブジェクトで、これはDataFrameオブジェクトとは異なります。
describe()のように両方のオブジェクトが持っているメソッドもありますが、例えば.loc[]プロパティはDataFrameオブジェクトは持っている一方でDataFrameGroupByオブジェクトは持っていません。
%matplotlib inlineの効果
%matplotlib inlineは、matplotlibで描画するグラフをインラインで表示させるための宣言のようです。
%matplotlib inlineを宣言しておくと、matplotlib.pyplot.show()を実行しなくても、自動でグラフが描画されるという特徴もあります。
matplotlib.org
Google Colaboratoryでのjapanize_matplotlibのインポート
Google Colaboratoryには、実はデフォルトでjapanize_matplotlibはインストールされていません。 なので、japanize_matplotlibを手動でインストールしたうえで、japanize_matplotlibをインポートする必要があります。
公式のページを参考に、
!pip install japanize_matplotlib
をインポートの前に実行しましょう。 colab.research.google.com
文字列関数名(string function name)
以下の記述のaggfunc='mean'や、
pre_data = pd.pivot_table(analyze_data, index='order_accept_month', columns='narrow_area', values='total_amount', aggfunc='mean') pre_data
以下の記述の.agg(['size', 'mean', 'median', 'max', 'min'])
store_clustering = analyze_data.groupby('store_id').agg(['size', 'mean', 'median', 'max', 'min'])['total_amount'] store_clustering.reset_index(inplace=True, drop=True) print(len(store_clustering)) store_clustering.head()
に現れる、文字列の'mean'や'size'は、"string function name"と呼ぶそうです。ググったところ「文字列関数名」と直訳されている例が出てきますが、あまりヒットしません。
これは、文字どおり、関数を指し示す文字列で、上記の例では引数にこれらを使用することができるようです。
pandas.pivot_table()の公式ドキュメントには
aggfunc: function, list of functions, dict, default numpy.mean If list of functions passed, the resulting pivot table will have hierarchical columns whose top level are the function names (inferred from the function objects themselves) If dict is passed, the key is column to aggregate and value is function or list of functions.
と記載がありますが、ここには「ピボットテーブルの最初の行には関数名が表示される」と書いてあるだけで、文字列関数名については何も書いてありません。 pandas.pydata.org
一方で、DataFrameGroupBy.agg()の公式ドキュメントには、
func : function, string, dictionary, or list of string/functions
Function to use for aggregating the data. If a function, must either work when passed a DataFrame or when passed to DataFrame.apply. For a DataFrame, can pass a dict, if the keys are DataFrame column names.
Accepted combinations are:
string function name.
function.
list of functions.
dict of column names -> functions (or list of functions).
と記載があり、この中の"string function name"というのが「文字列関数名」を指しています。ここにはしっかり「文字列関数名」を引数に渡していいと書いてあります。 pandas.pydata.org
これで改めて以下のコードを眺めると、
store_clustering = analyze_data.groupby('store_id').agg(['size', 'mean', 'median', 'max', 'min'])['total_amount']
analyze_dataを'store_id'でグルーピングしインデックスに並べ、- 残りのキーについてデータ数、平均、中央値、最大値、最小値を算出し、
'total_amount'のキーの列だけをstore_clusteringに代入 しているというのが理解できます。
…ここまでして思うのは、どうせ'total_amount'しか使わないんだったら、先に'total_amount'だけ抽出して、それに対して各種代表値を算出した方がいいのでは?と思うのだが、どうなんだろう?
一応、メソッドの順番を変えた以下のコードも実行してみましたが、こちらも問題なく動きました。 実行時間は体感では差はなかったです。
store_clustering2 = analyze_data.groupby('store_id')['total_amount'].agg(['size', 'mean', 'median', 'max', 'min']) store_clustering2
seaborn.jointplot()のプロット種類
seaborn.jointplot()のプロット種類は引数kindで指定します。
公式ドキュメントには以下のとおり、6種類の中から選ぶことができます。
kind{ “scatter” | “kde” | “hist” | “hex” | “reg” | “resid” } Kind of plot to draw. See the examples for references to the underlying functions.
テキストではkind='hex'でグラフを描いています。
kind='hex'の場合
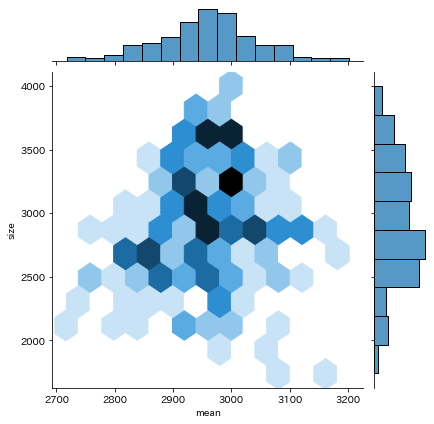
同じデータで他の種類を描画すると、以下のようになります。
kind='scatter'の場合(デフォルト)
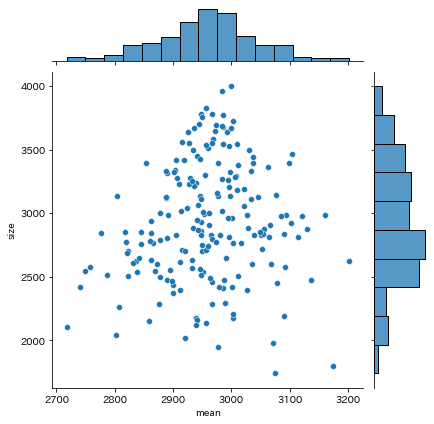
- 散布図を描画
- 外側にはそれぞれの軸のヒストグラム
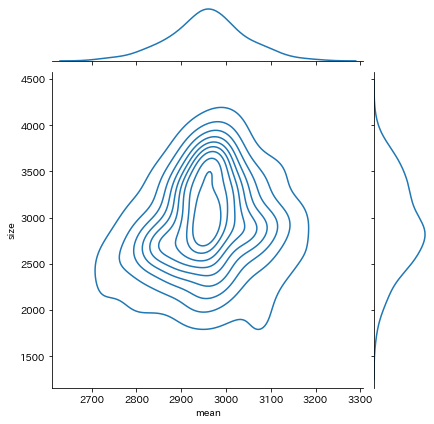
kind='kde'の場合
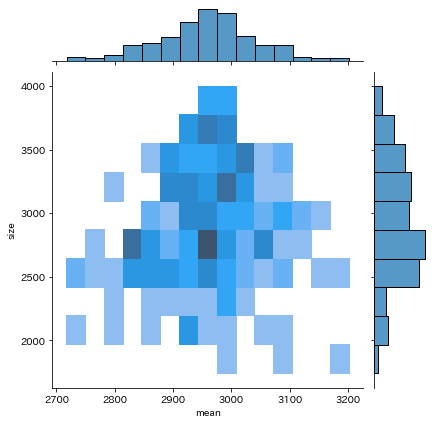
kind='hist'の場合
kind='reg'の場合
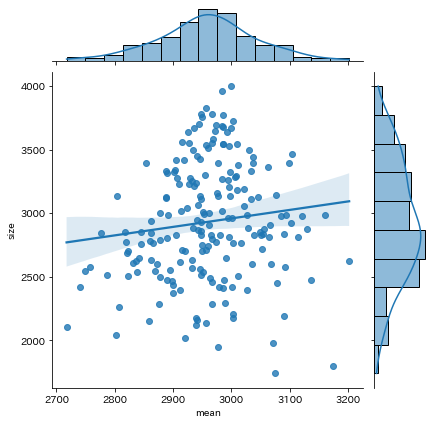
- 散布図に回帰直線を重ねたもの
kind='resid'の場合
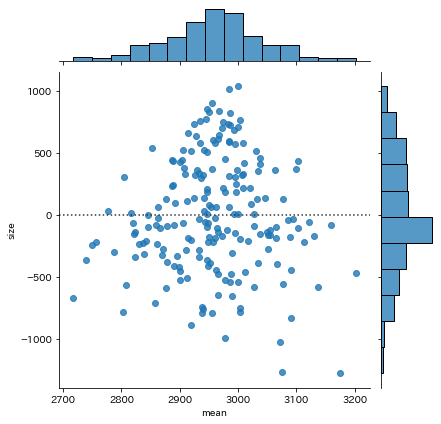
- y軸が回帰直線との残差(外側のヒストグラムも同じ)
末尾のアンダースコア(_)は予約語との重複避け
store_clustering['cluster'] = clusters.labels_
でk-meansの結果をstore_clusteringに新規で列'cluster'を作って代入していますが、
ここで使っている.labels_のプロパティにアンダースコア_がついています。
これは、仕様上、プロパティの名前がlabels_なのでそれをそのまま呼んでいるだけなのですが、
ではなぜlabelsとせずにlabels_としているのでしょう?
一般的に、名前の最後にアンダースコアがひとつついている場合は、メジャーな予約語との重複避けを理由とすることが多いそうです。 (これはPEP 8のコーディング規約に記載されているようです)
具体的にsklearn.cluster.KMeans.labels_が何との重複を避けているのかはよくわかりませんでした。
公式サイトを見ると、プロパティの名前はすべて末尾にアンダースコアを付けているようですので、
そういう方針なのかもしれません。
次の記事