Jupyter NotebookでStable Diffusionを遊びたい(その1:ChilloutmixのNotebookを読んでみよう)
いま巷で話題のStable Diffusionですが、私もこれで遊んでみたいなと最近になって思い、お手軽にGoogle Colaborateでいろんな画像を出して遊んでいました。
ところが、今日も遊んでみようとGoogle Colaborateを開いたら
 と、GPUの使用料上限を超えてしまっており、Stable Diffusionで遊べませんでした。
(右下の「GPUなしで接続」をクリックして、GPUなしでソースコードを動かそうとしても、途中で「GPUがないよ!」とエラーが出てしまい、動かすことができません。)
と、GPUの使用料上限を超えてしまっており、Stable Diffusionで遊べませんでした。
(右下の「GPUなしで接続」をクリックして、GPUなしでソースコードを動かそうとしても、途中で「GPUがないよ!」とエラーが出てしまい、動かすことができません。)
GPUを使うためには、Google ColaborateのGPU制限が解除されるまで待つしかありませんが、いつ解除されるのか、そのルールはGoogleからは明示されていません。非公式情報では、24時間程度までば解除されるとありますが、よくわからないというのが正直なところです。
幸いにして私のノートPCはゲーミングPCなので、貧弱ではありますが一応GPUが積んであります。なので、Google ColaborateのGPU制限を気にせずにStable Diffusionで遊べるように、ローカルのJupyter NotebookでStable Diffusionを動かせる環境を作ってしまおうと思います。
コードは以下のGitHubからDLしておきます。 github.com
私はChilloutmixを使うので、chilloutmix.ipynbを実行しようとしましたが、Google Colaborateでは何の問題もなく実行できたのが、ローカルのJupyter Notebook (anaconda 3)ではエラーで止まってしまいました。
仕方ないので、Notebookの内容をひとつひとつ追ってみます。
最初の行の
!curl -Lo memfix.zip https://github.com/nolanaatama/sd-webui/raw/main/memfix.zip
は、Linixのcurlコマンドと呼ばれるもので、client for URLからきています。
上のcurlコマンドはオプションで
-L:リダイレクトに対応し
-O:URL先をダウンロードする(ここではmemfix.zipというファイル名でダウンロードする)
と指示されているので、そのとおりに実行されます。
次の
!unzip /content/memfix.zip
も、Linuxコマンドunzipで、先ほどダウンロードしたZIPファイルを解凍しています。
このNotebookはGoogle Colaborate用ですので、ダウンロードしたファイルは/contentディレクトリの下にいます。
次の
!apt install -qq libunwind8-dev
は、aptを使ったlibunwind8-devのインストールです。
オプションで-qqが使われているので、ログの表示が最小限に抑えられています。
そのあとの
!dpkg -i *.deb
で、ダウンロードしたファイル内に含まれるすべtのdevファイルについてdpkg -iでインストールをしています。
%env LD_PRELOAD=libtcmalloc.so
で環境変数をとおして、最後に
!rm *
でダウンロードしたファイルをすべて削除しています。
C言語プログラマがPythonのお勉強で気になったことメモ(その3)
前回からの続きです。 stacked-tip.hateblo.jp
3章で気になって調べたこと
ipywidgetsのobserve()
ipywidgetsに含まれるウィジェットはobserve()というメソッドを持っています。
これは、ウィジェットが変化したときに実行するコールバック関数を登録することができるメソッドです。
テキストでは
dropdown.observe(order_by_store, names='value')
と書いてありますが、これはこの直前に定義したorder_by_store()関数をコールバック関数として登録しているのです。
なお、第2引数のnames='value'は、コールバック関数の引数として渡すものを名前で指定しています。
上記の例ではvalueをいう文字列を渡していますが、これは、dropdownの属性であるvalueを渡す、という意味です。
dropdownの属性であるvalueは、dropdownに関する情報を持っているリストです。具体的には
- name:名前
- old:変更前の値
- new:変更後の値
- owner:ウィジェット(今回の場合はdropdown)自身の情報
- type:イベント発生条件
が入っています。
テキストの例にあるorder_by_store関数の中で、
clear_output()
print(val)
のようにclear_output()の後でvalを表示してみると、具体的な中身が見えます。
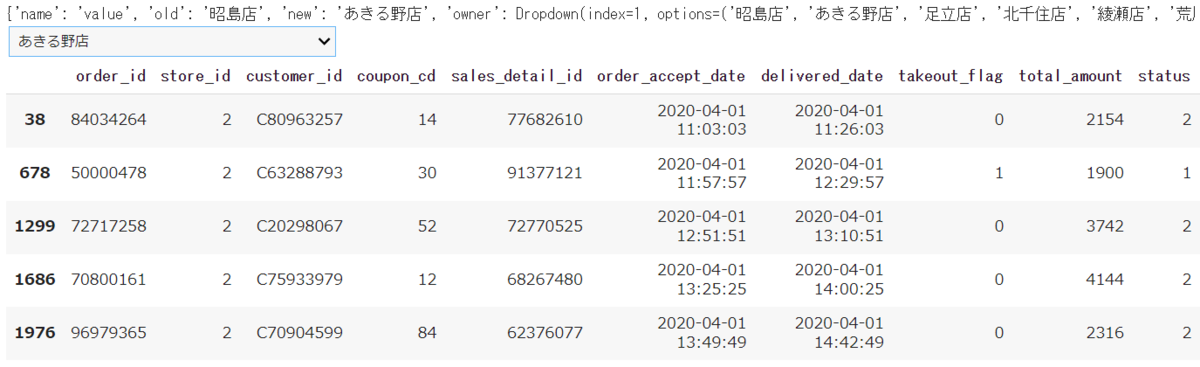
order_by_store関数の中で
pick_data = order_data.loc[(order_data['store_name']==val['new']) & (order_data['status'].isin([1,2]))]
と書いていますが、ここのval['new']とは変更後の値を指しています。
Pythonのグローバル変数・ローカル変数
#(前略) def order_by_multi(val): clear_output() display(select) pick_data = order_data.loc[(order_data['store_name'].isin(val['new'])) & (order_data['status'].isin([1,2]))] display(pick_data.head()) select = SelectMultiple(options=store_list) #(後略)
上のようなコードがテキストにありますが、ここで
display(select)
のselectは、関数定義の外にある
select = SelectMultiple(options=store_list)
のグローバル変数selectを指しています。
Pythonには、グローバル変数とローカル変数以外に「フリー変数」なる変数があるようです。 公式ドキュメントに"free variable"と書かれているものがそれです。 docs.python.org
この「フリー変数」ですが、公式ドキュメントを読んでもいまひとつ挙動がわからない。 Qiitaの記事等を参考にすると、どうやら、
- ブロックの外にある変数と同名の変数をブロックの中で読み込む→ブロックの中の変数はグローバル変数として扱われる
- ブロックの外にある変数と同名の変数にブロックの中で書き込む→ブロックの中の変数は同名で別のローカル変数として扱われる
という挙動のようです。
少し例を挙げます。
例1
def func(): print(hoge) hoge = 1 print(hoge) func() print(hoge)
これの結果は
1
1
1
です。
例2
def func(): hoge = 2 print(hoge) hoge = 1 print(hoge) func() print(hoge)
これの結果は
1
2
1
となります。
例3
def func(): print(hoge) hoge = 2 print(hoge) hoge = 1 print(hoge) func() print(hoge)
これの結果はエラーになります。
1
---------------------------------------------------------------------------
UnboundLocalError Traceback (most recent call last)
<ipython-input-11-532135ee2a15> in()
6 hoge = 1
7 print(hoge)
----> 8 func()
9 print(hoge)
<ipython-input-11-532135ee2a15> in func()
1 def func():
----> 2 print(hoge)
3 hoge = 2
4 print(hoge)
5UnboundLocalError: local variable 'hoge' referenced before assignment
C言語プログラマがPythonのお勉強で気になったことメモ(その2)
前回に引き続きです。 stacked-tip.hateblo.jp
今回も、こちらの書籍のコードを写経しながら、気になって調べたことを紹介していきます。
2章で気になって調べたこと
pandas.Series.dt.strftime()の引数のフォーマット
analyze_data['order_accept_month'] = analyze_data['order_accept_data'].dt.strftime('%Y%m')
で出てきましたpandas.Series.dt.strftime()は、要素を日付フォーマット(date format)に変換するメソッドです。
公式ドキュメントによれば、このメソッドの引数にはpython standard libraryに準拠したフォーマット文字列(そしてこれは1989 C standardをベースとしている)を入れるよう書いてあります。
%Yは4桁の年、%mは2桁の月を、それぞれ意味しています。
pandas.DataFrame.groupby()メソッドとDataFrameGroupByオブジェクト
pandas.DataFrame.groupby()メソッドを使うと、指定したキーの種類ごとにデータをグルーピングしてくれます。
このメソッドの返値はDataFrameGroupByオブジェクトという専用のオブジェクトで、これはDataFrameオブジェクトとは異なります。
describe()のように両方のオブジェクトが持っているメソッドもありますが、例えば.loc[]プロパティはDataFrameオブジェクトは持っている一方でDataFrameGroupByオブジェクトは持っていません。
%matplotlib inlineの効果
%matplotlib inlineは、matplotlibで描画するグラフをインラインで表示させるための宣言のようです。
%matplotlib inlineを宣言しておくと、matplotlib.pyplot.show()を実行しなくても、自動でグラフが描画されるという特徴もあります。
matplotlib.org
Google Colaboratoryでのjapanize_matplotlibのインポート
Google Colaboratoryには、実はデフォルトでjapanize_matplotlibはインストールされていません。 なので、japanize_matplotlibを手動でインストールしたうえで、japanize_matplotlibをインポートする必要があります。
公式のページを参考に、
!pip install japanize_matplotlib
をインポートの前に実行しましょう。 colab.research.google.com
文字列関数名(string function name)
以下の記述のaggfunc='mean'や、
pre_data = pd.pivot_table(analyze_data, index='order_accept_month', columns='narrow_area', values='total_amount', aggfunc='mean') pre_data
以下の記述の.agg(['size', 'mean', 'median', 'max', 'min'])
store_clustering = analyze_data.groupby('store_id').agg(['size', 'mean', 'median', 'max', 'min'])['total_amount'] store_clustering.reset_index(inplace=True, drop=True) print(len(store_clustering)) store_clustering.head()
に現れる、文字列の'mean'や'size'は、"string function name"と呼ぶそうです。ググったところ「文字列関数名」と直訳されている例が出てきますが、あまりヒットしません。
これは、文字どおり、関数を指し示す文字列で、上記の例では引数にこれらを使用することができるようです。
pandas.pivot_table()の公式ドキュメントには
aggfunc: function, list of functions, dict, default numpy.mean If list of functions passed, the resulting pivot table will have hierarchical columns whose top level are the function names (inferred from the function objects themselves) If dict is passed, the key is column to aggregate and value is function or list of functions.
と記載がありますが、ここには「ピボットテーブルの最初の行には関数名が表示される」と書いてあるだけで、文字列関数名については何も書いてありません。 pandas.pydata.org
一方で、DataFrameGroupBy.agg()の公式ドキュメントには、
func : function, string, dictionary, or list of string/functions
Function to use for aggregating the data. If a function, must either work when passed a DataFrame or when passed to DataFrame.apply. For a DataFrame, can pass a dict, if the keys are DataFrame column names.
Accepted combinations are:
string function name.
function.
list of functions.
dict of column names -> functions (or list of functions).
と記載があり、この中の"string function name"というのが「文字列関数名」を指しています。ここにはしっかり「文字列関数名」を引数に渡していいと書いてあります。 pandas.pydata.org
これで改めて以下のコードを眺めると、
store_clustering = analyze_data.groupby('store_id').agg(['size', 'mean', 'median', 'max', 'min'])['total_amount']
analyze_dataを'store_id'でグルーピングしインデックスに並べ、- 残りのキーについてデータ数、平均、中央値、最大値、最小値を算出し、
'total_amount'のキーの列だけをstore_clusteringに代入 しているというのが理解できます。
…ここまでして思うのは、どうせ'total_amount'しか使わないんだったら、先に'total_amount'だけ抽出して、それに対して各種代表値を算出した方がいいのでは?と思うのだが、どうなんだろう?
一応、メソッドの順番を変えた以下のコードも実行してみましたが、こちらも問題なく動きました。 実行時間は体感では差はなかったです。
store_clustering2 = analyze_data.groupby('store_id')['total_amount'].agg(['size', 'mean', 'median', 'max', 'min']) store_clustering2
seaborn.jointplot()のプロット種類
seaborn.jointplot()のプロット種類は引数kindで指定します。
公式ドキュメントには以下のとおり、6種類の中から選ぶことができます。
kind{ “scatter” | “kde” | “hist” | “hex” | “reg” | “resid” } Kind of plot to draw. See the examples for references to the underlying functions.
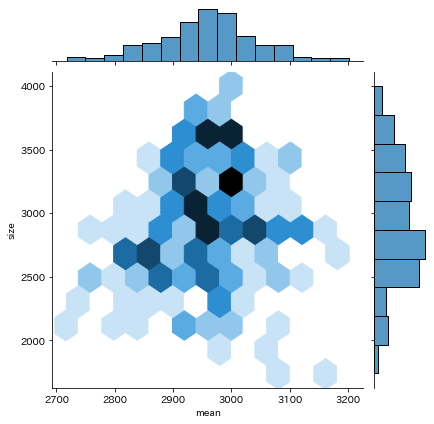
テキストではkind='hex'でグラフを描いています。
kind='hex'の場合
同じデータで他の種類を描画すると、以下のようになります。
kind='scatter'の場合(デフォルト)
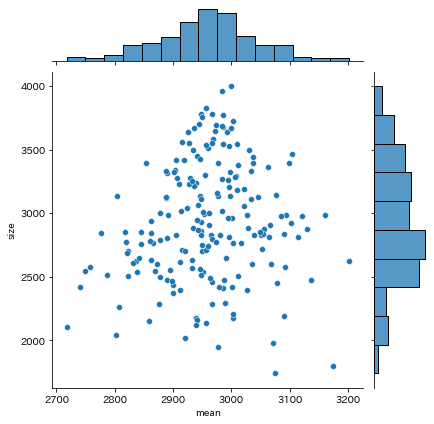
- 散布図を描画
- 外側にはそれぞれの軸のヒストグラム
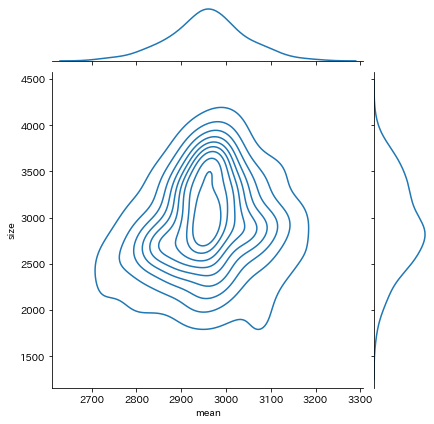
kind='kde'の場合
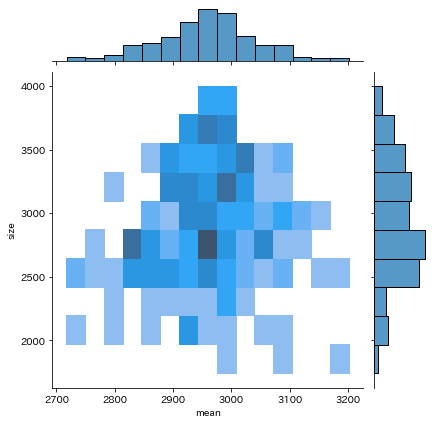
kind='hist'の場合
kind='reg'の場合
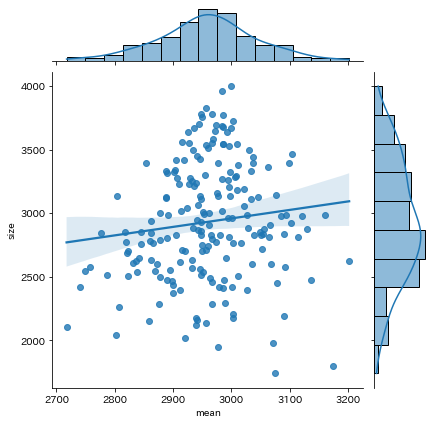
- 散布図に回帰直線を重ねたもの
kind='resid'の場合
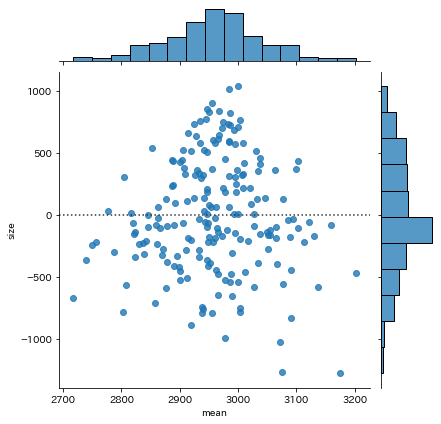
- y軸が回帰直線との残差(外側のヒストグラムも同じ)
末尾のアンダースコア(_)は予約語との重複避け
store_clustering['cluster'] = clusters.labels_
でk-meansの結果をstore_clusteringに新規で列'cluster'を作って代入していますが、
ここで使っている.labels_のプロパティにアンダースコア_がついています。
これは、仕様上、プロパティの名前がlabels_なのでそれをそのまま呼んでいるだけなのですが、
ではなぜlabelsとせずにlabels_としているのでしょう?
一般的に、名前の最後にアンダースコアがひとつついている場合は、メジャーな予約語との重複避けを理由とすることが多いそうです。 (これはPEP 8のコーディング規約に記載されているようです)
具体的にsklearn.cluster.KMeans.labels_が何との重複を避けているのかはよくわかりませんでした。
公式サイトを見ると、プロパティの名前はすべて末尾にアンダースコアを付けているようですので、
そういう方針なのかもしれません。
次の記事
C言語プログラマがPythonのお勉強で気になったことメモ(その1)
データサイエンティストを目指すべく、Pythonを学習することにしました。
Pythonはturtleでちょっと遊んだことがあるくらいで、ほぼ初心者みたいなものです。
一時期tkinterで遊んでいた時期もありましたね、今思い出しました。
さてPythonの情報はWeb上にたくさんありまして、公式のチュートリアルドキュメントを読むだけでもある程度の文法はわかります。
docs.python.org
ただし、どうしても実践的な面に欠けるので、書籍を買って勉強することにしました。
今回購入したのは以下の本です。
環境構築
このテキストはJupyter NotebookあるいはGoogle Colaboratoryの使用を想定しています。
私は手っ取り早く使えるGoogle Colaboratoryでコーディングすることにしました。
1章で気になったこと
とりあえず1章に掲載されているコードを順番に写経してみました。
テーブル管理とか、応用情報技術者試験の勉強で触ったこともないSQL文法をやったのを思い出します。
ひとまず、気になって調べたことをつらつらと書いていきます。まぁメモなので。
asはライブラリを別名をつけて呼び出すための予約語
import pandas as pd m_store = pd.read_csv('m_store.csv')
というのがありますが、pythonのasは別名(エイリアス)をつけてライブラリを呼び出すための予約語のようです。
上の例でいえば、pandasというライブラリを呼び出し、それにpdという別名をつけているのです。
これは、このあとでいちいちpandasと書くのが面倒なので、その略記としてpdを使うのであって、
べつに別名をつけずに全部pandasと書いてもコードは動いてくれます。
import pandas m_store = pandas.read_csv('m_store.csv')
注意しなくてはいけないのは、asは、ライブラリを呼び出してから別名をつけているのではなく、
別名をつけてライブラリを呼び出しているという点です。
なので、以下のコードはエラーになります。pdという名前でpandasを呼び出したので、この時点で使えるライブラリの名前はpdのみだからです。
import pandas as pd m_store = pandas.read_csv('m_store.csv')
concatはconcatenateのこと
order_all = pd.concat([tbl_order_4, tbl_orer_5], ignore_index=True)
のconcatは英語で「連結」を意味する"concatenate"から来ています。
「コンケイトネイト」と読みたいですが、発音記号はkənkǽtənèitで、カタカナ的には「コンキャトネイト」です。
公式ドキュメントをみると、引数は最低限objsがあればOKなようです。
pandas.concat(objs, axis=0, join='outer', ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, sort=False, copy=True)
objsについては、
objs: a sequence or mapping of Series or DataFrame objects
と説明があり、SeriesorDataFrameの配列あるいはマッピングを入れなさい、とのことです。
先ほどの例でも、連結したい2つのDataFrameをリストにして[tbl_order_4, tbl_orer_5]の形で渡していますね。
(ちなみにpandas.read_csv()は読み込んだCSVファイルをDataFrame形式で返してくれるそうです。)
cwdはカレントワーキングディレクトリのこと
import os
current_dir = os.getcwd()
current_dir
で使われているos.getcwd()の"cwd"は"current working directory"の略のようです。
カレントディレクトリを指す言葉が、言語によってcdだったりcwdだったりするので、ホントはどちらかに統一してほしいですね。
「ユニオン」はconcat()、「ジョイン」はmerge()
データの結合を意味する言葉として「ユニオン」「ジョイン」の2つが出てきます。
これはSQLをはじめとするデータベースの用語です。
対応するpandasのメソッドはそれぞれconcat()とmerge()です。
ちなみに、ファイルパスを作成するところで
tbl_order_file = os.path.join(current_dir, 'tbl_order_*.csv')
tbl_order_file
でjoin()が出てきますが、これはまた別のメソッドです。
globは「かたまり」という意味
import glob
tbl_order_files = glob.glob(tbl_order_file)
tbl_order_files
で出てくる"glob"は、英語で「かたまり」という意味だそうです。
glob.glob()について、公式ドキュメントには
Return a possibly-empty list of path names that match pathname, which must be a string containing a path specification.
とあるので、マッチするパスをリスト形式で出力してくれるようです。
マッチするパスがなければ、空のリストを返すようです。
docs.python.org
f''はフォーマット済み文字列リテラル
print(f'{file}:{len(order_data)}')
に出てくるf''はPython 3.6で追加された新機能である「フォーマット済み文字列リテラル」、通称「f-string」だそうです。
実行時に{}の中を評価してくれるので、上記の例のように関数を入れることもできます。
DataFrameの行・列を指定して取得する方法
order_all['total_amount'].describe()
を実行することで、キーが'total_amount'の列を取得し、それのdescribe()を出力してくれます。
ところで列の取得はキーを指定すればいいようなのですが、行の取得はどうすればいいのでしょうか?
どうやさスライスを[]に入れてあげると、行のインデックスと認識してくれるそうです。
order_all[0:1]
を実行することで、インデックス0の行を出力してくれます。
(スライスm:nは「m以上n未満の整数」という意味ですから、0:1は0のみを指します。)
スライスでなければ行のインデックスと認識されないので、以下のコードはエラーになります。
order_all[0]
locはlocationのこと
order_data = order_all.loc[order_all['store_id'] != 999]
によって、列'store_id'が999ではない行すべてを抽出しています。
ここで使われているloc[]は"location"のことです。
DataFrame.loc[]は、最後が[]で終わっています。
実はDataFrame.loc[]はメソッドではなくプロパティであり、
[]で終わっていることからわかるとおり、リスト形式のプロパティです。
今回は2次元のリスト(配列)になります。
2次元のリストに対して、数字を1つ渡すと行の指定になります。
order_all.loc[0]
とすると、インデックスが0の行が出力されます。
order_all.loc[0:2]
とすると、インデックスが0~2の行、あわせて3行が出力されます。
(あれ?なんでなんだ?)
数字を2つ渡すと、1つ目の引数が行を、2つ目の引数が列を指定します。
order_all.loc[:5, 'order_id']
と書くと、インデックスが0~5までの6行のうち、列のキーが'order_id'のものが出力されます。
列だけを指定したい場合は、以下のようにすればOKです。
order_all.loc[:, 'order_id']
先ほどの
order_data = order_all.loc[order_all['store_id'] != 999]
の例に戻ると、これは[]の中に,がありませんから、行だけを指定しています。
そして、行の指定方法として、order_all['store_id'] != 999が書かれています。
order_all['store_id'] != 999は一体なんなのかというと、
order_all['store_id']で抽出した列の各要素に対して、999と一致しないかどうかをTrueかFalseのリストで返すというものです。
出力はこんな感じ。

これをloc[]に入れると、Trueの行だけ、つまり、999と一致しなかった行だけを返すことになります。
また、loc[]に存在しない行・列を入力することで、行・列を新規に追加することもできます。
order_data.loc[order_data['takeout_flag']==0, 'takeout_name'] = 'デリバリー' order_data.loc[order_data['takeout_flag']==1, 'takeout_name'] = 'お持ち帰り'
のところとかがそうですね。
続きです。
stacked-tip.hateblo.jp
Σa^2≧((Σa)^2)/nの証明
個の実数
、
、…、
があるとき、
が成り立つことを、数学的帰納法を用いて証明する。
1) の場合
また、
よって、のとき、与えられた不等式は成り立つ。(常に等号成立)
2) の場合に、与えられた不等式が成り立つと仮定する。すなわち、
が成り立つと仮定する。
このとき、
…①
ところで、について、
が成り立つので、
①…②
となる。
また、
なので、
②
ゆえに、
が成り立ち、
のときも、与えられた不等式が成り立つ。
なお、等号成立条件は、
のとき。すなわち、
が、
から
までの平均と等しいときである。
1)、2)より、数学的帰納法により、すべての自然数について、
は成り立つ。
等号成立条件は、以下のすべての自然数
において、
が、
から
までの平均と等しいときである。
これは、のときに
が
から
までの平均と等しい、すなわち、
であることから、
を意味する。
繰り返しのある一元配置実験結果の単回帰分析方法(その2:2つの方法で導出される寄与率)
前回の記事では、繰り返しのある一元配置実験の結果に対して単回帰分析を行う際、データ処理の方法として2つの方法を紹介した。
いずれの方法であっても、得られる回帰直線式は同じであることを示した。
stacked-tip.hateblo.jp
分散分析や寄与率(決定係数) は?
は?
単回帰分析をする際には、回帰式の有意性を判断するために、分散分析結果や寄与率を確認する。
回帰直線式が同一であっても、分散分析結果や寄与率に差があると、実用上は解析結果の意味が変わってしまうことになる。
分散分析表は、以下のようにまとめる。
| 要因 | 平方和 |
自由度 |
平均平方 |
|
| 計 |
ここで算出されたを、
(
は危険率)と比較して、帰無仮説
を棄却するかどうかを決める。
また、寄与率は次の式から算出する。
以下、2つの方法で分散分析結果や寄与率に差があるか確認する。
結論から言えば、2つの方法で、総平方和に差がある。
また、自由度も異なるため、
 と
と をペアとする
をペアとする 個のデータを用いる方法の場合
個のデータを用いる方法の場合
総平方和は、
となる。これは、さらに式変形することで、
となる。
また、回帰による平方和は、
であり、残差平方和は
で求めることができる。
これらの平方和の自由度は、それぞれ
である。
と をペアとする
をペアとする 個のデータを用いる方法の場合
個のデータを用いる方法の場合
前節の各統計量と区別するため、それぞれにダッシュ(プライム)を付けて表記する。
総平方和は、
となる。これは、さらに式変形することで、
となる。
また、回帰による平方和は、
であり、残差平方和は
で求めることができる。
これらの平方和の自由度は、それぞれ
である。
ここまでの結果を表にまとめて比較する。
| 統計量 | 方法1 | 方法2 |
| 総平方和 | ||
| 回帰による平方和 | ||
| 残差平方和 |
ここで、以下の不等式が成り立つことを利用する。
個の実数
、
、…、
があるとき、
が成り立つ。
証明は、以下の記事を参照のこと。
stacked-tip.hateblo.jp
この不等式を用いると、
が成り立つことがわかる。
これを用いると、
となり、
が証明できる。
前回の記事で示した
を用いると、
となる。寄与率は、
となり、
であることがわかる。
繰り返しのある一元配置実験結果の単回帰分析方法(その1:2つの方法で導出される回帰直線式)
繰り返しのある一元配置実験を行うとする。
水準が、
、…、
の合計
個あり、
それぞれについて回繰り返し評価を行った結果、
、
、…
、
、
、…、
の、合計個の結果を得たとする。
また、各水準の結果の平均を計算する。
表にまとめると以下のようになる。
| 1回目 | 2回目 | … | n回目 | 平均 | |
| … | |||||
| … | |||||
| … |
今、を説明変数、
を目的変数とする単回帰分析を行いたい。
モデル式をとし、
は互いに独立に
に従うこととする。
このとき、単回帰分析の方法として、
の2種類の方法が考えられる。
この2種類の方法にはどのような違いがあるのかを確認する。
なお、本記事は、永田靖『入門 統計解析法』を大いに参考にしています。

母回帰係数の推定値
母回帰係数の推定値
について考える。
は、
と
の偏差積和
と、
の偏差平方和
を用いて、
で求めることができる。
とをペアとする個のデータを用いる方法の場合
、
とすると、
となる。
の各項について、さらに式変形をすると、
となるので、
となる。
また、についてもさらに式変形をすることで、
となる。
とをペアとする個のデータを用いる方法の場合
先述の、
と区別するため、それぞれにダッシュ(プライム)を付けて、
、
とする。
それぞれを、さらに式変形することで、
となる。
以上の計算から、
の関係があることがわかる。
したがって、どちらの場合であっても、の値は同一にあることがわかる。
母切片の推定値
母切片の推定値
は、
から算出される。
したがって、どちらの方法であってもの値が同一である以上、
についても、どちらの方法であっても値は同一となる。
結論
母回帰係数、母切片ともに、どちらの方法で求めても同じ値が得られるということは、
これらの期待値]、
]や分散
]、
]についても、
どちらの方法であっても同一である。
したがって、
のどちらの方法であっても、得られる回帰直線式は同じである。